Reference
[1] J. Deng, J. Guo, N. Xue, and S. Zafeiriou, “Arcface: Additive angular margin loss for deep face recognition,” in CVPR, 2019, pp. 4690–4699.
[2] Michal Geyer, Omer Bar-Tal, Shai Bagon, and Tali Dekel. Tokenflow: Consistent diffusion features for consistent video editing.
[3] S. Yang, Y. Zhou, Z. Liu, and C. C. Loy, “Rerender a video: Zero-shot text-guided video-to-video translation,” in SIGGRAPH Asia 2023 Conference Papers, 2023.
[4] H. Ouyang, Q. Wang, Y. Xiao, Q. Bai, J. Zhang, K. Zheng, X. Zhou, Q. Chen, and Y. Shen, “Codef: Content deformation fields for temporally consistent video processing,” CVPR, 2024.
[5] M. Ku, C. Wei, W. Ren, H. Yang, and W. Chen, “Anyv2v: A plug-and-play framework for any video-to-video editing tasks,” TMLR, 2024.
[6] B. Peng, J. Wang, Y. Zhang, W. Li, M.-C. Yang, and J. Jia, “Controlnext: Powerful and efficient control for image and video generation,” arXiv preprint arXiv:2408.06070, 2024.
 We present Qffusion, a simple yet effective dual-frame-guided portrait video editing framework. Specifically, our Qffusion is trained as a general animation framework from two still reference images whereas it can perform portrait video editing effortlessly when using modified start and end video frames as references during inference. That is, we specify editing requirements by modifying two video frames rather than text. In this way, our Qffusion can perform fine-grained local editing (e.g., modifying age, makeup, hair, style, and wearing sunglasses).
We present Qffusion, a simple yet effective dual-frame-guided portrait video editing framework. Specifically, our Qffusion is trained as a general animation framework from two still reference images whereas it can perform portrait video editing effortlessly when using modified start and end video frames as references during inference. That is, we specify editing requirements by modifying two video frames rather than text. In this way, our Qffusion can perform fine-grained local editing (e.g., modifying age, makeup, hair, style, and wearing sunglasses).
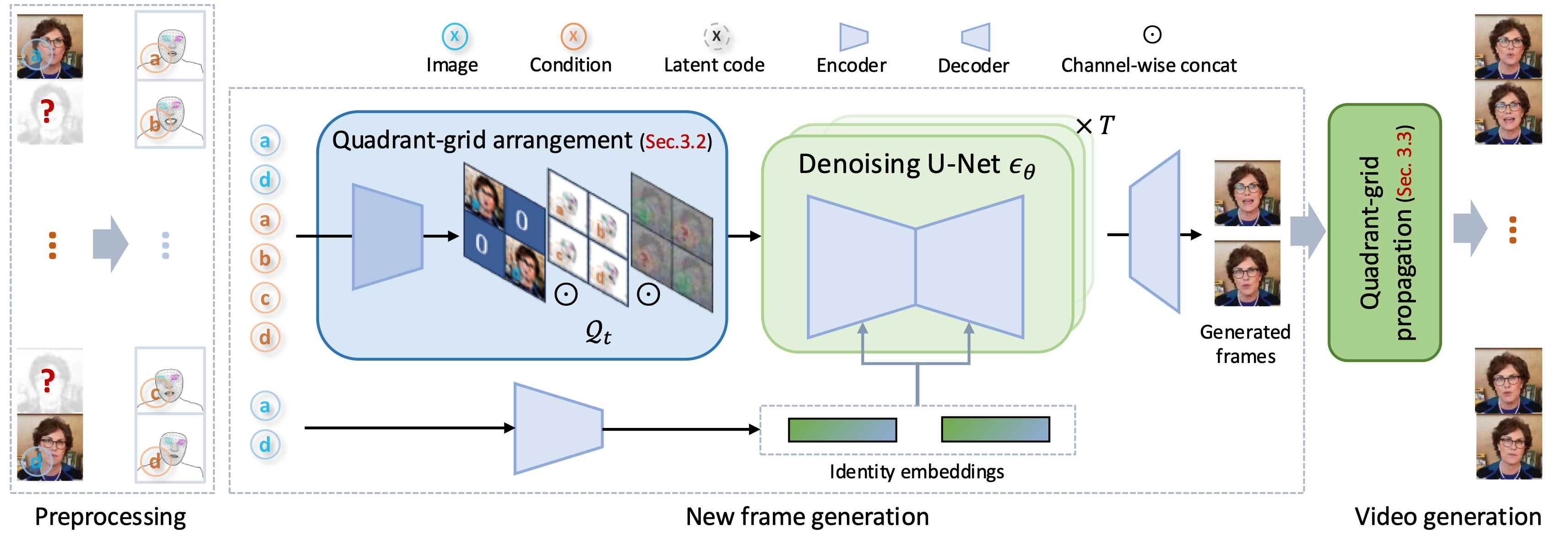 Overview illustration of Qffusion. As for training, we first design a Quadrant-grid Arrangement (QGA) scheme for latent re-arrangement, which arranges the latent codes of two reference images and that of four portrait landmarks into a four-grid fashion, separately. Then, we fuse features of these two modalities and use self-attention for both appearance and temporal learning. Here, the facial identity features [1] are also put into cross-attention mechanism in the denoising U-Net for further identity constraint. During inference, a stable video is generated via our proposed Quadrant-grid Propagation (QGP) strategy.
Overview illustration of Qffusion. As for training, we first design a Quadrant-grid Arrangement (QGA) scheme for latent re-arrangement, which arranges the latent codes of two reference images and that of four portrait landmarks into a four-grid fashion, separately. Then, we fuse features of these two modalities and use self-attention for both appearance and temporal learning. Here, the facial identity features [1] are also put into cross-attention mechanism in the denoising U-Net for further identity constraint. During inference, a stable video is generated via our proposed Quadrant-grid Propagation (QGP) strategy.